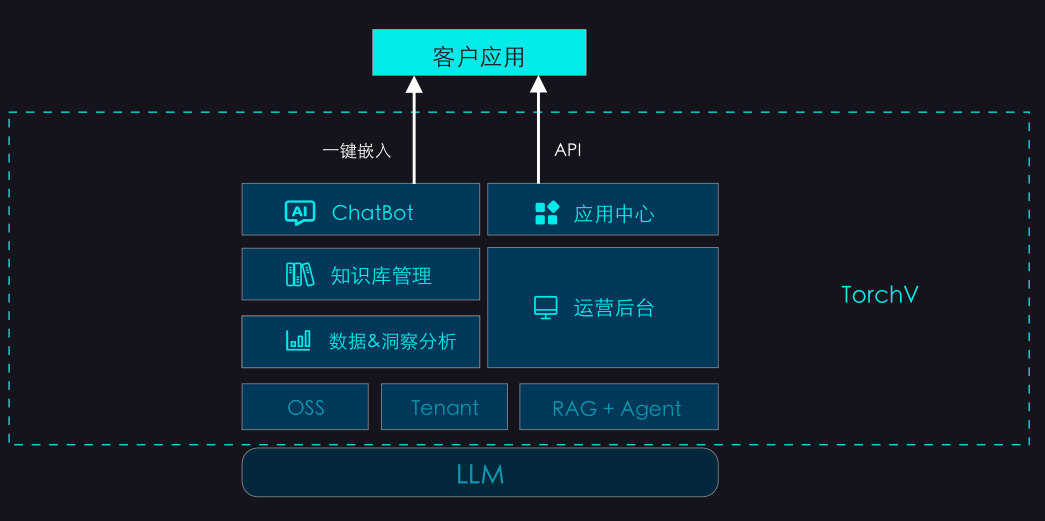
作者:肖玉民,杭州萌嘉网络科技有限公司联合创始人&CTO。团队长期专注于企业 AI 落地与 AI 知识引擎实践,是国内较早探索 RAG 企业应用落地的团队之一。产品 TorchV 已成功服务浪潮信息、微众银行、物产中大国际贸易、物产中大金属、台州银行、适途汽车、中汇税务师事务所等客户。
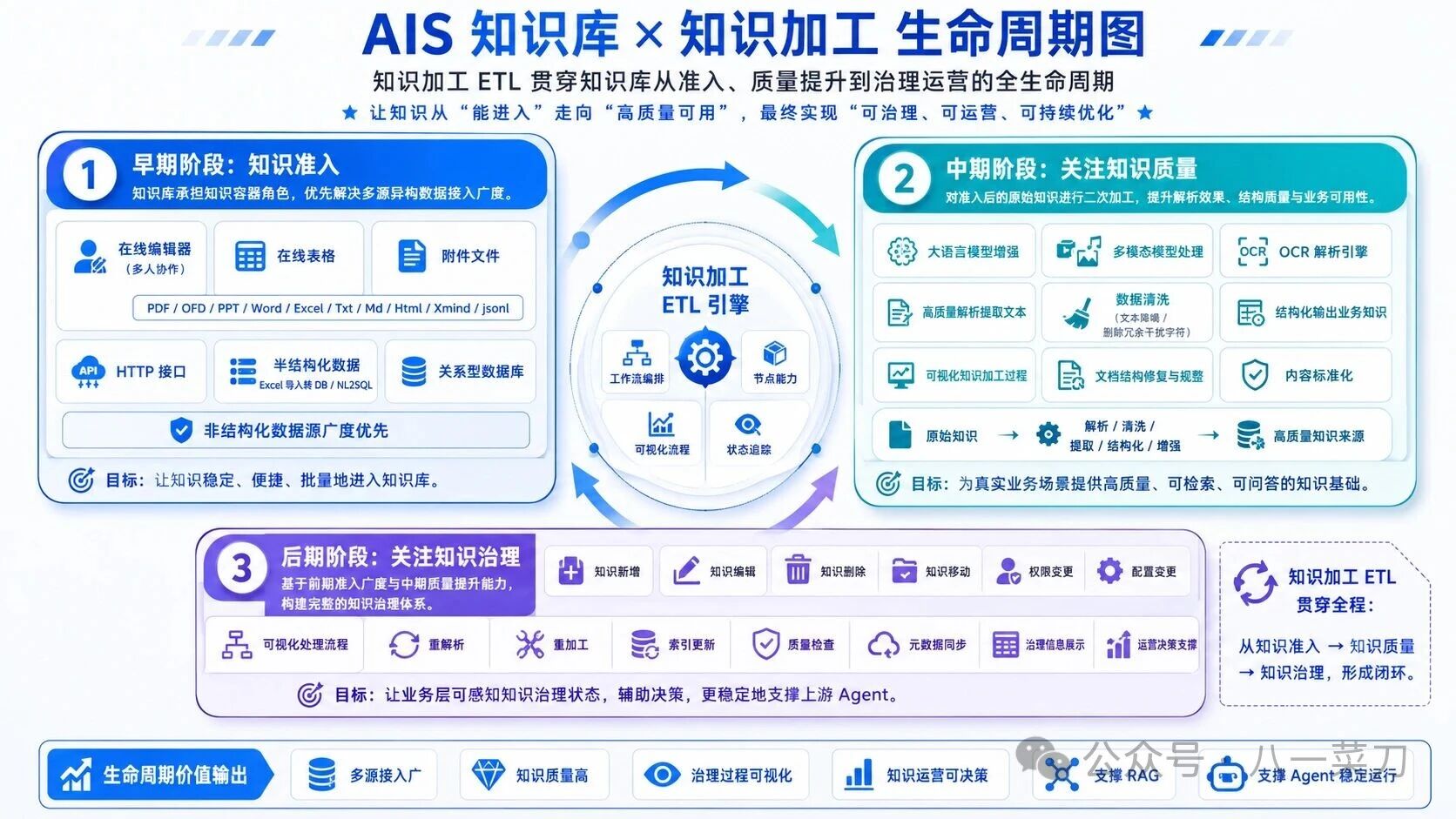
我觉得在知识库里面,以知识加工来驱动知识库三个生命周期的阶段:
1、早期阶段(知识准入)
知识库需要起到容器的作用,对于知识准入来说,知识库系统需要支撑多种数据源的导入处理请求,要求的是对文件的支撑的广度,AIS知识库在这个阶段,提供了非常多的数据类型支撑,包括:在线编辑器(多人协作)、在线表格、附件(支持PDF、OFD、PPT、Word、Excel、Txt、Md、Html、Xmind、jsonl等文件)、HTTP接口等多种数据源的、半结构化数据(Excel导入转DB走Nl2SQL的方式)、关系型数据库。我们是支持的非结构化数据源的广度优先。
2、中期阶段(关注知识质量)
在中期阶段,我们发现了第一阶段的数据,可能无法支撑业务在真实的环境,这里面包括数据的质量不好,文档解析效果不佳,源文件内容结构、排版糟糕等等诸多问题,此时我们关心对于知识,希望借助外部大模型、多模态模型、OCR解析引擎等等先进的AI技术手段,提供对知识的二次加工处理,这里面包括数据的清洗(文本降噪/删除冗余干扰的字符)、结构化输出业务知识、可视化知识加工过程、高质量的解析提取文本等等内容,都是为了提高我们知识准入阶段,为业务做好高质量的知识来源,提供支撑。
3、后期阶段(关注知识治理)
在知识库的后期,我们有了知识准入的广度,也提供了知识质量的一系列标准技术手段方法,此时围绕知识库,就可以构建完整的知识治理体系。真是因为有了前期2个阶段的铺垫工作,后期的知识治理做起来才会得心应手。通过知识加工ETL,能够贯穿整个知识库的生命周期,从知识准入、知识质量、知识治理。三个维度,都可以提供标准的ETL的节点,对知识库的知识的新增、编辑、删除等动作,提供可视化的处理流程,业务层也能关注到知识库的文件治理的信息,做出决策,更好的支撑起上游